Making Open-Data Useful
Lessons from Diagram Chasing
If you can’t see the projector, slides are at
https://aman.bh/to/indiafoss


Who is My Neta?
Easy and intuitive explorer for browsing affidavits and parliamentary activity of elected MPs.

India Time Use Explorer
We cleaned up the dataset and made it so that you can answer any query without code.
Run complex aggregations and SQL queries all in-browser in a GUI.

Who spends more time cleaning up after meals?


It’s never been easier to spin up a dashboard for your open-data with a few prompts.

It’s also never been easier for your audience to ignore yet another dashboard.

For the first time, search through thousands of censorship records
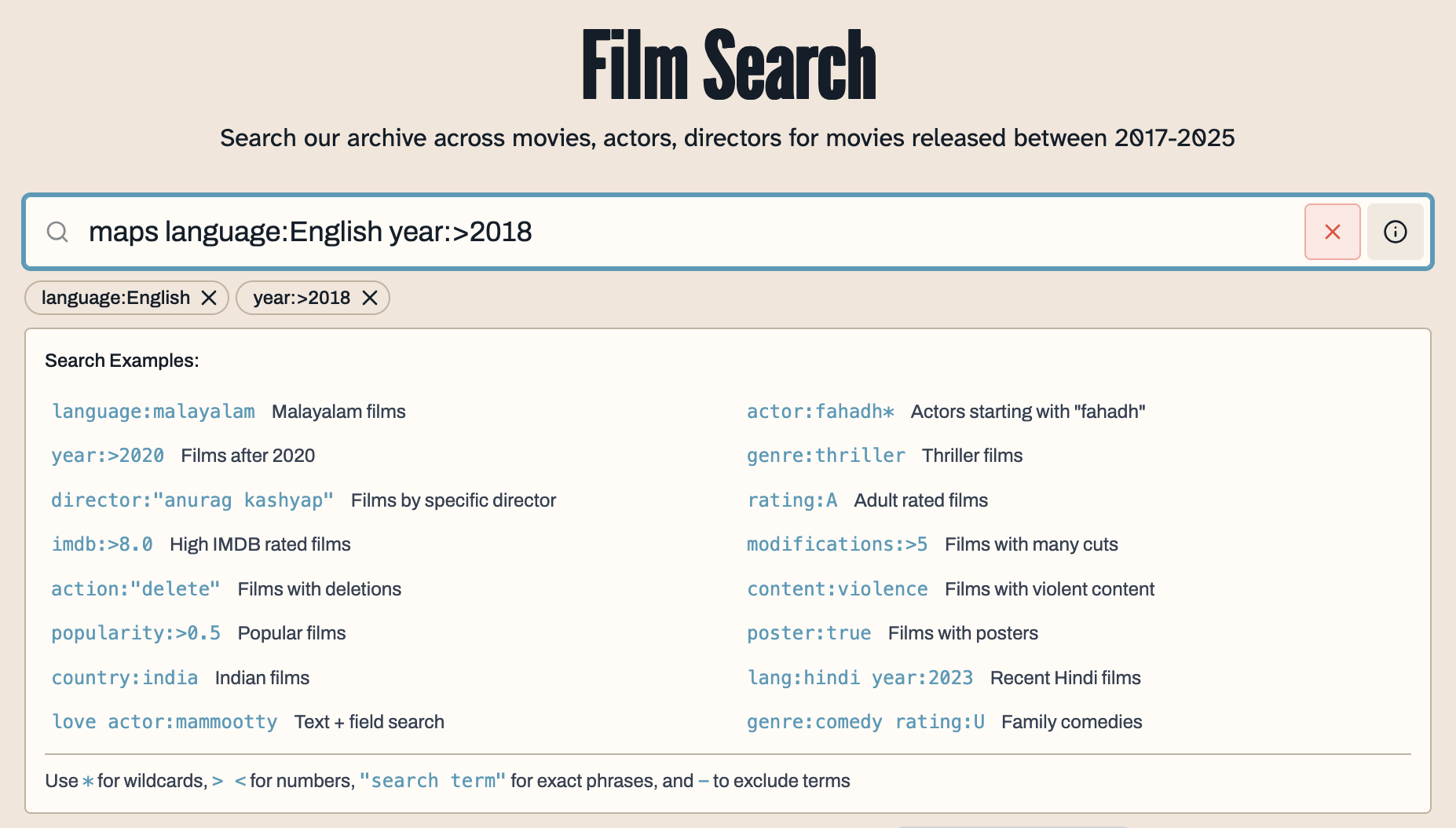
Browse cross-referenced keywords
Each film leads you to others like it, creating links between 18,000 movies based on censorship

Understand a film in context
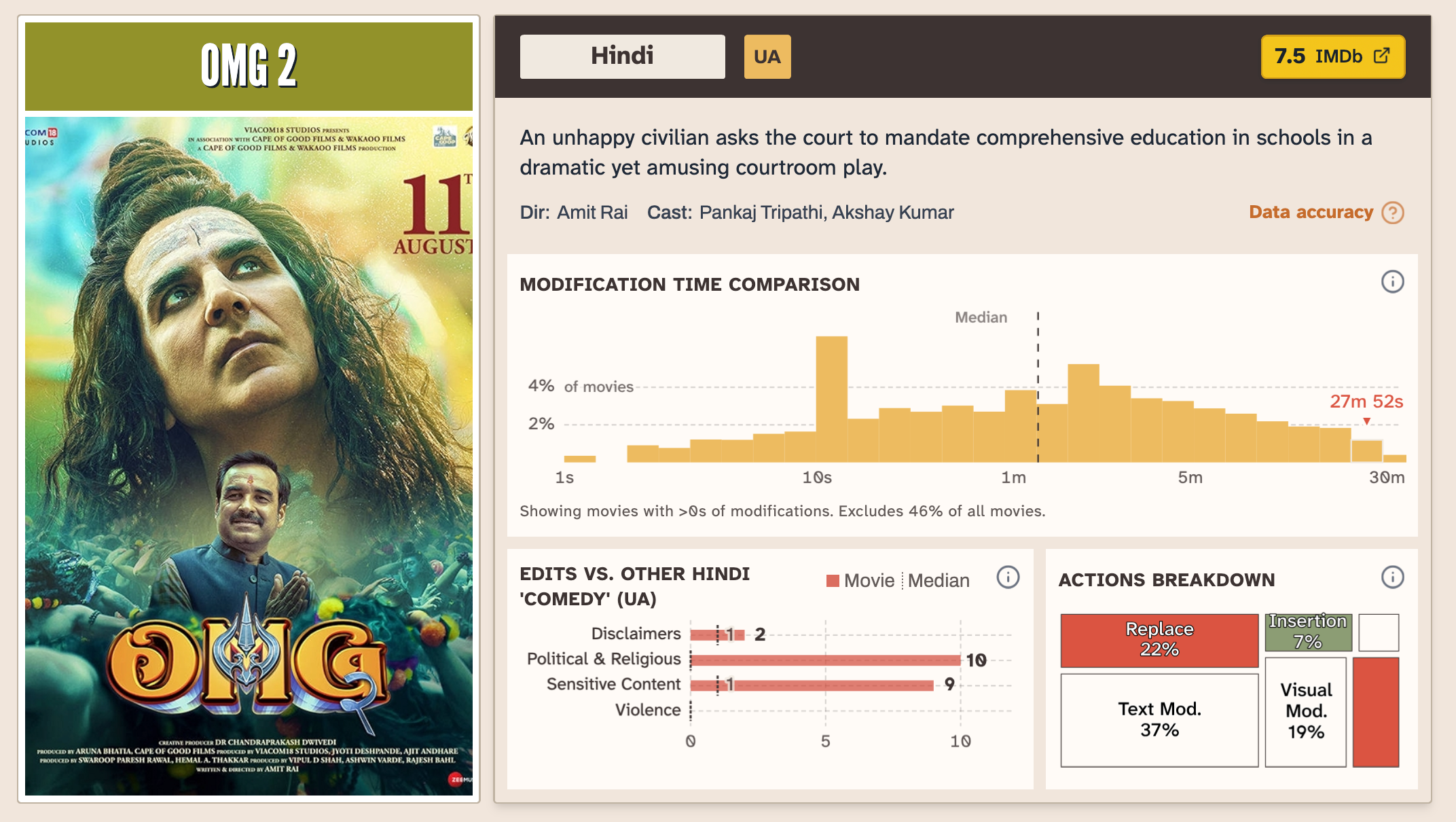
Normally the only way to find a certificate for a movie is to go around searching for something like this in a theatre

On opening the URL, the certificate is displayed with the list of cuts made to the film.

HAR Files
HAR is a convenient format to record the API calls for a page
- Developer Tools → Network Tab
- Load the target page containing data of interest
- Save all as HAR

There are many ways to go from a HAR file to a functional scraper
One quick way is to feed it to an LLM and prompt it to write a scraper
Works surprisingly well most of the time!

Soon enough, we had a functional scraper

Making it human readable
- Build a parser to read HTML files
- Extract only the relevant content
- Export everything to CSV format

This data was still unusable because the information that users cared about was hidden in piles of text and timestamps with no context.
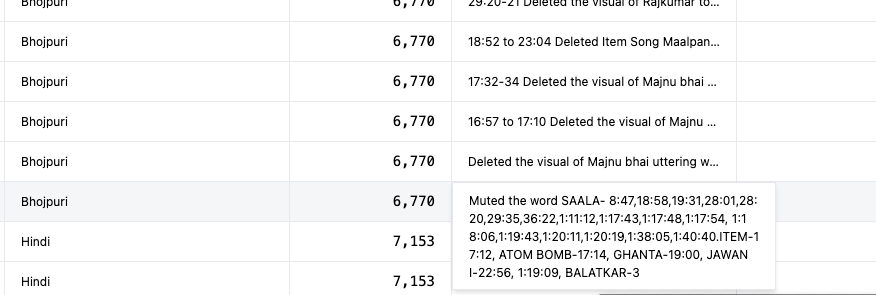
Attempt #1:
Manual Classification

Typesense, a powerful self-hosted FOSS alternative to Algolia.
Since we needed almost every field of the metadata to be searchable, we needed to come up with a solution to minimize the UI surface.
This is bad

Extra time spent perfecting search.
Let users make queries like they would in Google, we’ll do the complex operations.
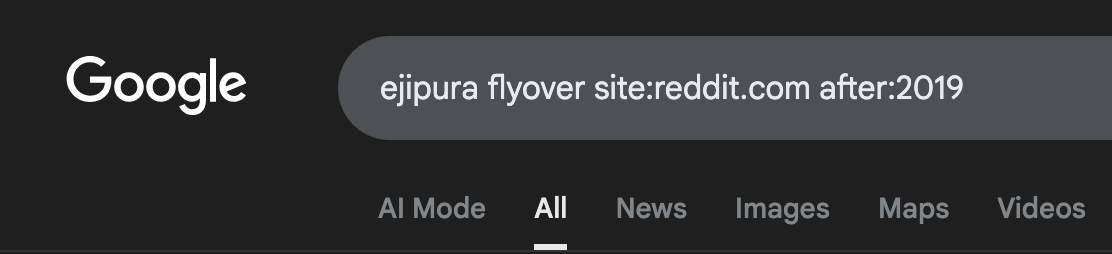
Show them one way to slice the data. Get them thinking of more!

We extensively document all data releases because we want users to use this data.
No guesswork.

Detailed notebooks! Ready-to-go
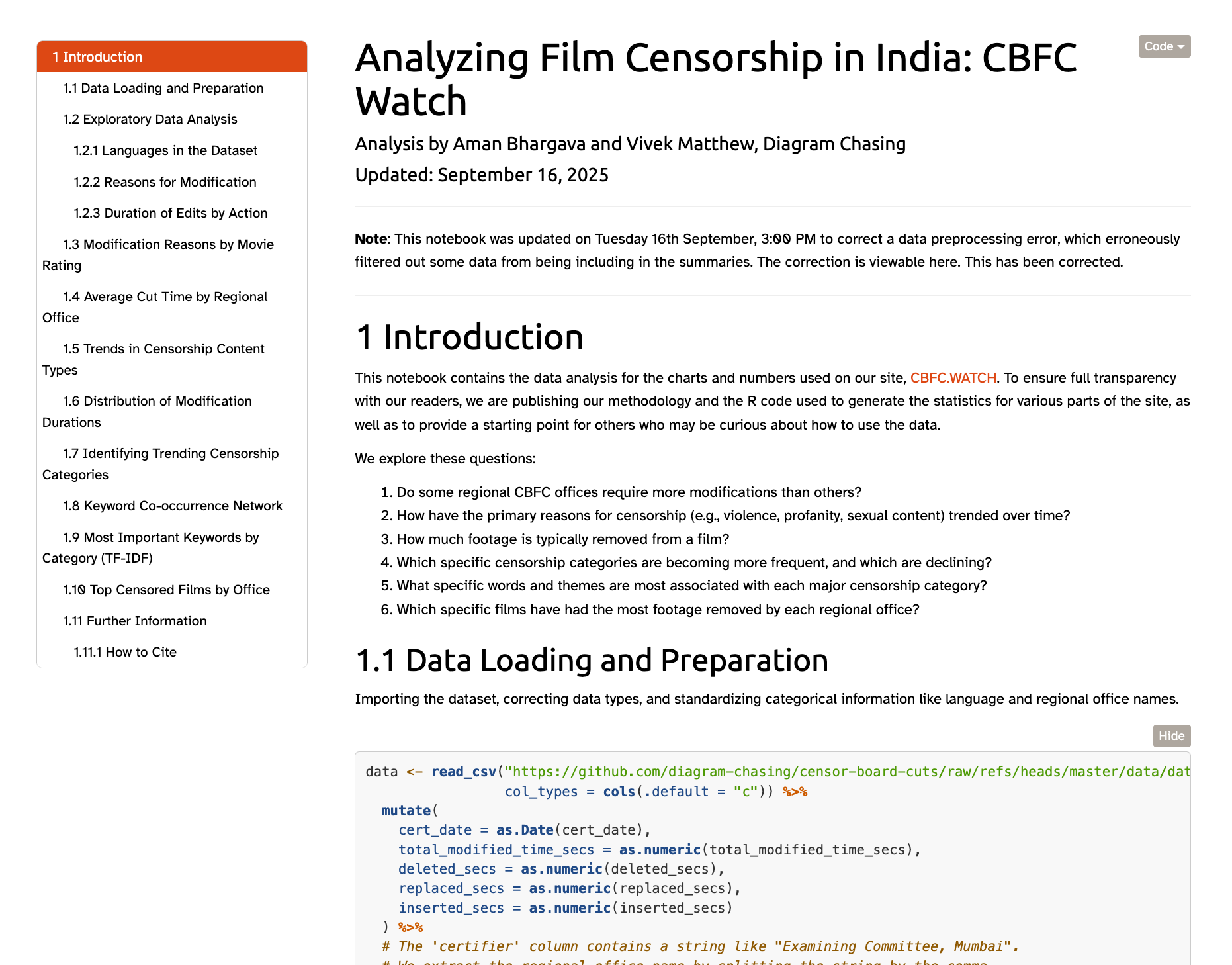
Documentation promotes use
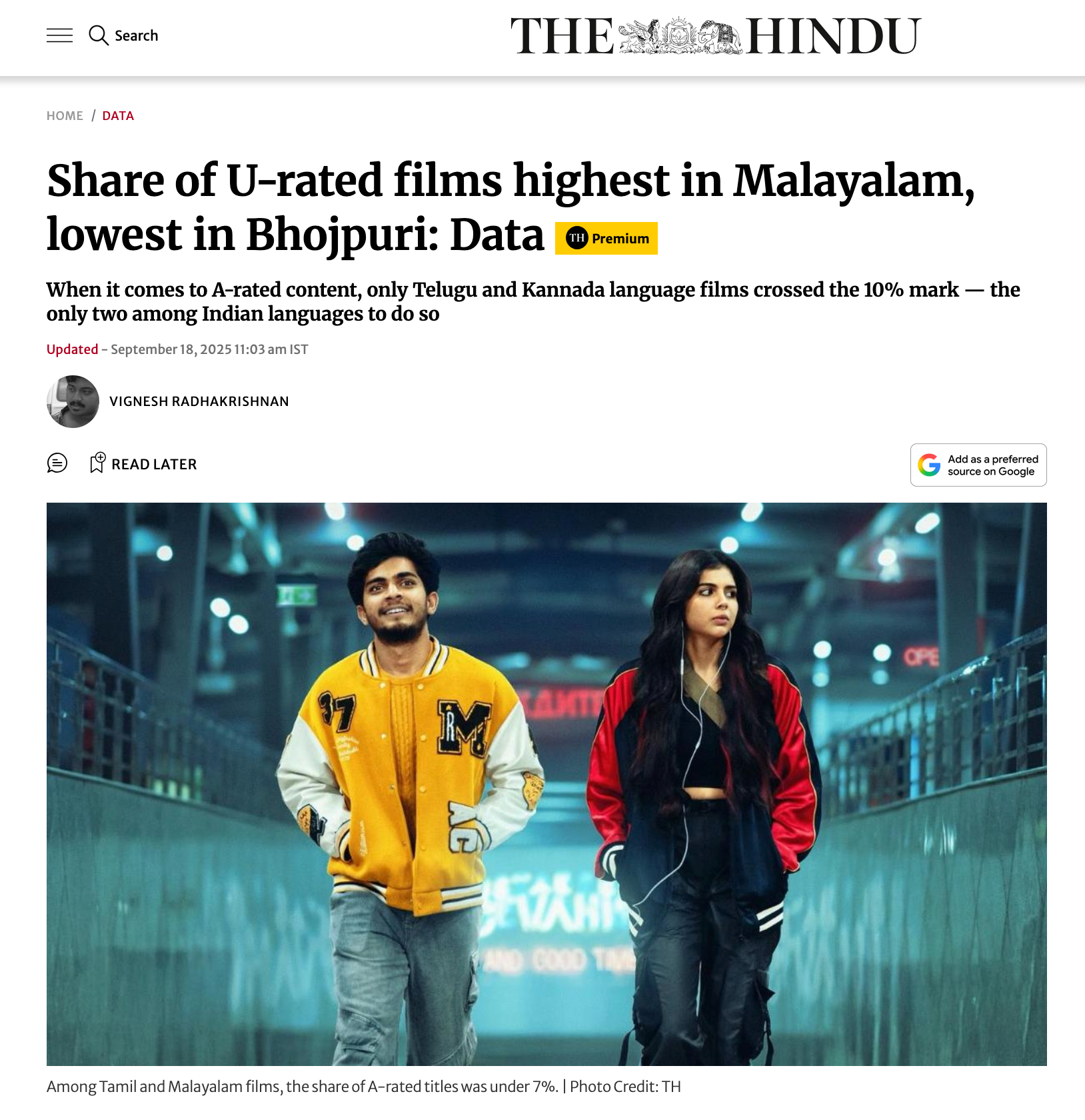
Documentation promotes use
Documentation promotes use

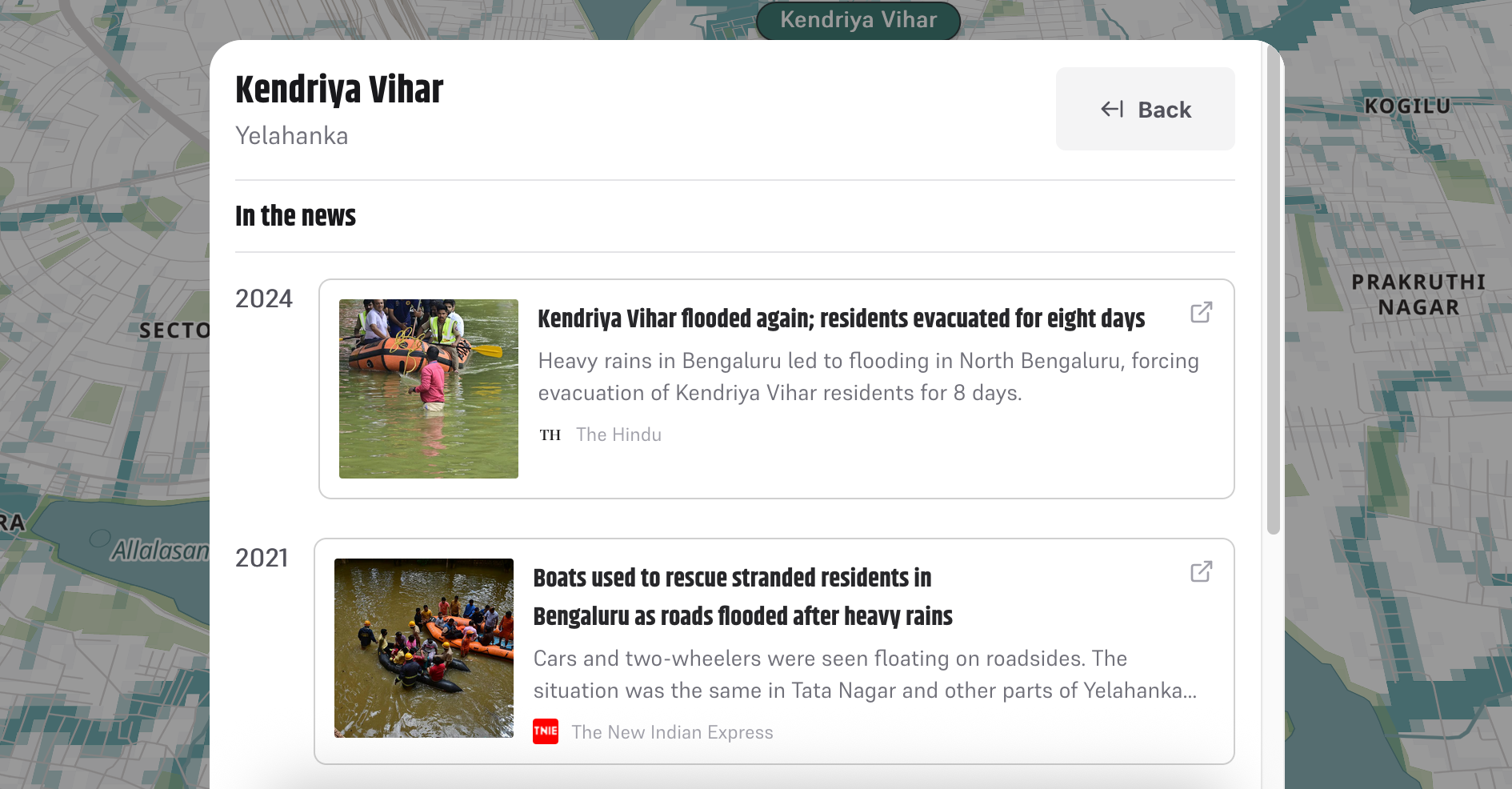
OpenStreetMaps in comparison…
Meet people where they are: in the browser!
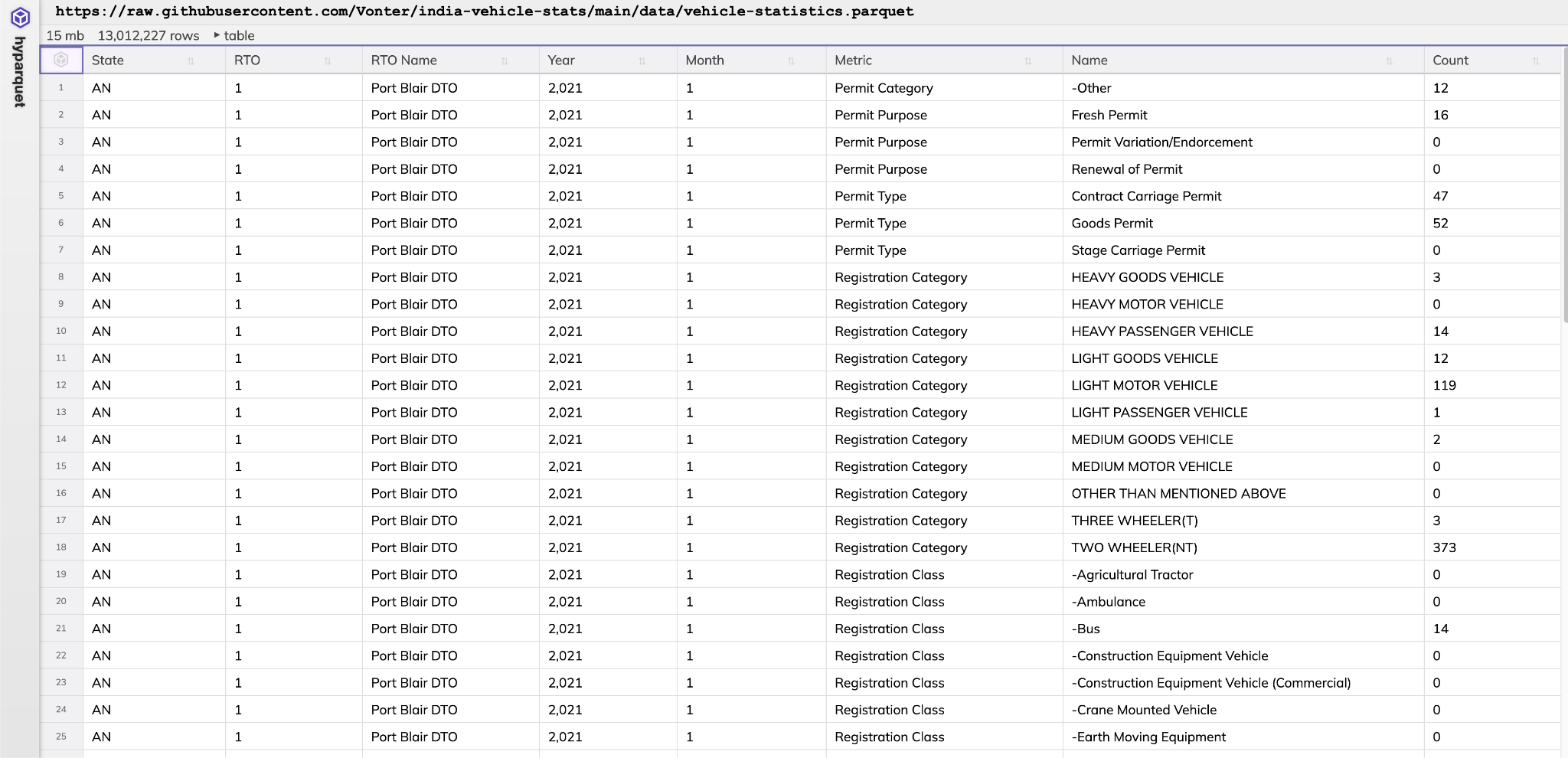
FlatGithub, HyParquet let people see the data without downloading.
Combining datasets creates better value
Individual datasets have limited utility and good context comes from joining multiple sources.
- ADR (Election Affidavits)
- PRS (Parliamentary Activity)
- MPLADS (Developmental Spending)

It might not even be a “dataset”

Thanks for listening!
diagramchasing.fun